Entropy Shmear
Consider the 1 MB of concatenated raw JPEG samples from the Photonic Instrument.
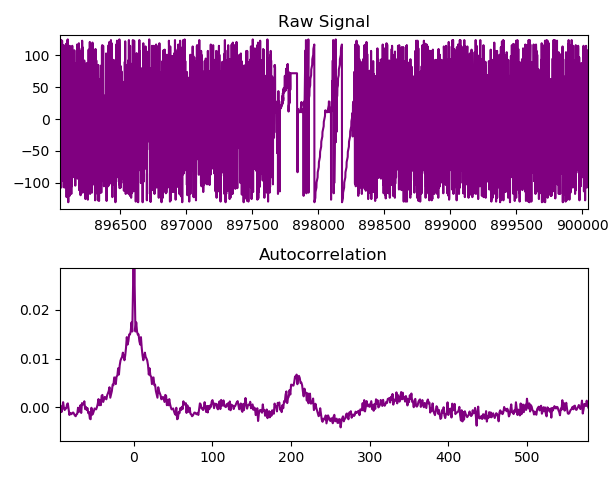
Naive application of Shannon’s $H = -K\sum_{i} {p_i \log p_i}, \enspace i \in \{0, 1\}^n$ entropy equation suggests a Shannon entropy rate of = 7.67 bits/byte for the JPEGs if $n=8$ (as is typical). A cmix compression estimate is only 5.17 bits/byte. What has happened to the missing 2.5 bits of Shannon entropy estimated to be in each byte? Our/an alternative way of thinking about auto correlation is that the missing 2.5 bits of entropy supposedly within each 8 bit window are elsewhere; outside of that narrow 8 bit window of consideration. The missing shmeared bits break the IID criterion, overlapping with many other bytes. We could say with enthusiasm and a grin that:-
- Each byte does contain 5.17 bits of true entropy based on scan windows for $n \gg 8$.
- The missing 2.5 bits are shmeared out across adjoining bytes and words due to auto correlation.
- They live outside of the enumeration of $i$, due to it’s 8 bit window (a probability distribution $P(\text{JPEG})$ based on $n = 8$).
- Thus the common means of applying Shannon cannot see nor account for them.
Our novel Entropy Shmear ($ES$) metric can be calculate as:-
- Let $\pi$ be the concatenated file of JPEG frames (1,077,644 bytes).
- Compute the entropy $H_{compression}(\pi)$ measured via
cmixcompression as $ \frac{|Cmix(\pi)| - k}{|\pi|} \times 8$. $|Cmix(\pi)| = 697,126 $ bytes in this case. - And $k$ is a constant representing the compressor’s file overhead, found from $ |Cmix(u)| - |u| $. 67 bytes in this case for
cmix. - $u$ is a good pseudo random file such as that from
/dev/urandom, of length equivalent to $|\pi|$. - Hint: use ent to measure $H_{Shannon}(\pi)$. 7.67 bits/byte in this case.
- The entropy shmear due to auto correlation $ES = \frac{H_{Shannon} - H_{compression}}{H_{Shannon}} $. That is $\frac{7.67 - 5.17}{7.67} $ or 33% for our $\pi$ sample.
Clearly in an IID situation, $ H_{Shannon} - H_{compression} - k \approx 0 $ [1]. Obviously an approximation, but might $ES$ be an alternative way of viewing auto correlation? We could say that $\pi$ has an auto correlation coefficient of >0.01. Or we can imagine 33% of $\pi$’s bits that would have made an IID sequence, being shmeared out to adjacent bytes. 33% of any byte in $\pi$ is strongly dependant on others.
{kind=link}
Anyway, it’s a thought isn’t it ¯\_(ツ)_/¯
Notes:
[1] An ent test of 1.2 MB of /dev/urandom samples showing that auto correlation is never exactly zero, even for cryptographically strong pseudo random sequences :-
$ ent /tmp/u
Entropy = 7.999855 bits per byte.
Optimum compression would reduce the size
of this 1200000 byte file by 0 percent.
Chi square distribution for 1200000 samples is 242.00, and randomly
would exceed this value 71.10 percent of the times.
Arithmetic mean value of data bytes is 127.5589 (127.5 = random).
Monte Carlo value for Pi is 3.144180000 (error 0.08 percent).
Serial correlation coefficient is 0.000989 (totally uncorrelated = 0.0).[2] And the correlation coefficient is inversely proportional to the length of an IID test sequence. This is a problem for DIY TRNG builders as the entropy sources we have resources to build cannot easily produce Gigabytes of test data. The Arduino-Entropy-Library produces “approximately two 32-bit integer values every second”. It would take over 41 hours to generate a similar 1.2 MB sample! Even the venerable HotBits only produces entropy at $\approx$ 800 bps.